原因は分かりました。各ユーザーに割り当てられた記憶容量が多分インターネット無かった時代ぐらいしかない。フロッピーディスクのような感じです。保存量の問題があるとはいえこんなに少ないとは、有料化したらマシになるんだろうか。
「いいね!」 2
AIも使える タスク管理出来るアプリというかサイト見つけました
これも使っていこうと思います
「いいね!」 3
DLについて学びなおししてますがやはりうまくいかないですね。ハイパーパラメーターの設定が悪いのか、データ整形手法が悪いのか、はたまた学習モデルが悪いのかまったくわかりませんね。プロの人はこの辺全部変数にしてGPUパワーで解決してるんだろうか。野良AIエンジニアにはまだ難しいのかな。
「いいね!」 1
いまのところ、一回の会話でAIが記憶できる容量には限界があり、基本的には、その会話が終了したら、次の新しい会話に入ると、記憶喪失になる仕様なので、毎回同じことを言わないといけないという、頭が良い認知症の人と会話する感じになりがちですよね。
そのうち長期メモリが使えるようになるみたいですけど、(いまでも、プロジェクト?みたいな機能がGPTに有料であるらしく、そこに過去の問答集をストックできるとかできないとか?)当面はサーバーの都合もあって、なかなかむずかしそうですね。まぁ、ローカルLLMだと可能かもしれませんけど、それでも大量のストレージが必要でしょうし、ここが解決しないと、本格的な運用は難しそうな気がします。
「いいね!」 3
なるほど、割としられた問題なんですね。みんなAI使いまくってるから容量が足りないのかな。
一応長期記憶のキャッシュを全削除したらメモリーが開放されてその後うまくはいきました。
今はディープラーニングしてるんですが、なかなかうまくいきません。
ハイパーパラメーター、データ整形、仮想データ構築、学習モデルの選定なんかで悩んでます。この辺効率的に学習するにはどうしたらいいのか。。
トレードみたいに繰り返し学習してコツつかむのが一番なのかな。
「いいね!」 2
ハイパーパラメーターについて色々調べてるとOptunaという自動ハイパーパラメーター最適化装置がある模様。(最初に教えてくれよ!)
一個一個解決してくか。
AIの言う通り時系列のダミーデータを作るモデルを作ってみたんだけどできたのはSMA、DLでモデル作ると毎回SMAができるのはなんなのw
SMAすきすぎだろ。
10時間以上かけて作ったのに失敗したのは痛い。費用的には100円ぐらいなのでそれほど痛くは無いな、タイパを考えたら上位モデルのGPU利用した方がいいのかも知れない。
何か作ってたモデルがデータ生成に向かない模様。今日はTIMEGANを試してみることにする。
AIサポートがあるにもかかわらず初期モデルを作るのに1日かかってしまった。
さあうまく生成されるかな。
「いいね!」 1
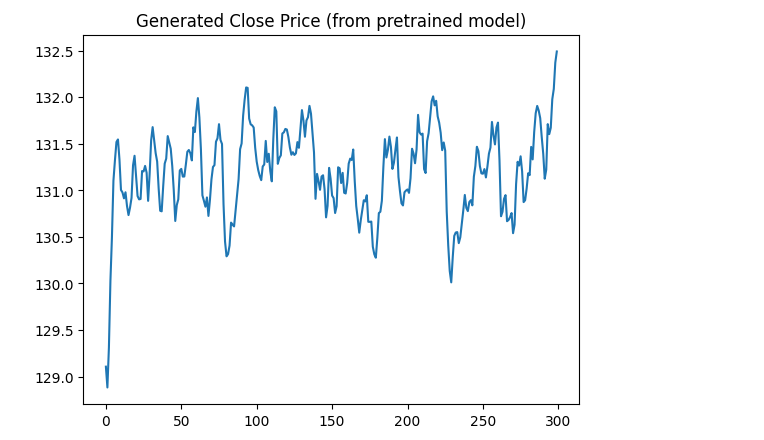
学習データからねうごきをさいげんできたぞぉぉぉ、ショック的値動きもはいってる
と喜んでたら3000件ぐらい表示すると

価格が同じ範囲に偏りすぎですし、ショックが上だけだし、ショックの値がほぼ同じ規模。これならT分布から生成した方がよさそうなきもする。むずかしいな。
「いいね!」 2

さあ今日も始まるぞ
今日はうまくいきます用に
しかし、AIもハルシネーションが多くて結局のところ何かしようとすると学部レベルもしくは修士レベルの数学が必要になってくることが多いな。
後レンタル費用との兼ね合いでRTX3090を使うか4090使うか悩み中だったけど4090でいって見よう。
ちょっとまて、これ並列処理もいけるのかRTX3090並列でいくか4090単体でいくかの選択肢もあるわけか
Vast.aiの韓国系は酷い。毎回起動に数十分とられる。今日は起動もできなかった。今度から韓国系はやめよう。台湾。タイ。大体うまくいく。なぜか韓国系は毎回エラーや起動が遅い。バッチサイズやサンプリングの調整等、初期設定だけで2時間かかってしまった。ETAは6時間ちょっと、明日の朝までには結果が出る模様。この小規模モデルトライ後、1日かかる大規模モデルに挑戦。
4090でメモリ不足でプロセスが死んだ。600円ぐらいかけてなにもできなかった、いたたたた。何か大航海時代の船団派遣的な感じになってきたな。
「いいね!」 1
ぎぎぎぎぎGPUでRandom Selectは基本されずにCPUでされるだと。
データ量の多すぎて間引きたい場合はGPUだけじゃなくて
超高性能のCPUを用意しないといけないわけか。
プログラム側で制御できるんだろうか。
PandasやNumpyは便利だけど小規模開発向けでデータ数が大きくなると
TFなどをベースに使う必要があるようだ。
失敗した。1000円ほど使ってなんの結果もでなかったどころか
すべてプロセスが途中ですべて死んだ。
理由としてはGPUのメモリが足りなかったり。色々反省点は多い。
- numpy, pandasは大規模データは処理できずにTFを使う必要があること
- データのランダム選抜はTFを使わないとCPU側で処理されてしまうこと
- プログラムの途中でハングしてしまった場合途中からやり直すようなプログラムになっておらず途中でのモデル保存がまったくできなかったこと。
最悪3さえ何とかすれば途中で問題出てもいい、と言うかこれを実装しないとレンタル環境で大容量データを使ったDLはかなり難しい。
数日はここでつまりそうだなこれは。
「いいね!」 2
また、CPUスペック不足でプロセスとんだ。割と嫌なボトルネックだなこれは。4090のPCならCPUもスペックよくて飛ばない可能性が高いからこっちにいくか。
しかしランダム摘出という割とありがちなプロセスがCPU処理されるってのが納得いかねぇ。
PANDAS<>TFの変換も割と重いらしいので。いちどTFに直してからランダム摘出を行ってPANDASに再変換するのも割と重いらしい、どのハードウェアに負荷がかかるのかもやって無いからわからないが、できれば答えを知らずに終わりたい。
てかCPUも単位コアの出力がでかいの選んだ方がいいんだろうか、とりあえず16コアにしてみたけど、処理分産されてなかったらただの貧弱1コアで処理されそう。
あああ、70%ぐらいでプロセス死んだ。JYUPITER経由だからダメなのかなこれ。CUI経由でもう一度やってみてダメなら機器変えるか。
だめだな、摘出データ削ってみたけどダメ。3090は諦めて4090にすることにする。
初の日本サーバー利用。ログインできず。日韓には呪いでもかかってんのか。
ロシアも試したが起動せず。
タイとかベトナムとか台湾の方がまともに動くのはちょっとおもしろいな。大体まともに動くサーバーは約6割ぐらいな気がする。SSHとSCP試して動かなければ即次に行った方がいい。
起動・ログインできない国
韓国X2
日本X1
ロシアX1
台湾鯖で無事通る。台湾鯖の安定度がぱない。準備まで10分以下です。韓国鯖とか日本鯖だと立ち上げでそれくらいかかる。CPUのボトルネックも無事通過。朝飯行ってくるか。
先ほども言ったが、プロセスが開始されてて、無事動いた。9分の1終わるのに大体1時間かかったのでETAは翌日0時ぐらいか
待ってる時間暇なのでStable diffusionをためしてみた。最初Pytorchの入ってるテンプレートからインストールを試みたが失敗。調べてるとSDが入ってるTemplate
SD WebUI A1111 軽量版
SD WebUI Forge 多機能版
があるようだ。これで試してみるか。